This section describes the disaster recovery mechanisms of an active-active cluster in the event of node and network failures, as well as the impact on services. For physical disk and NIC failures, the impact and handling methods are the same as those in clusters without the active-active feature enabled. For details, refer to the corresponding sections of this manual.
This section uses a typical active-active cluster in the same geographical area, consisting of nine nodes as an example, in which:
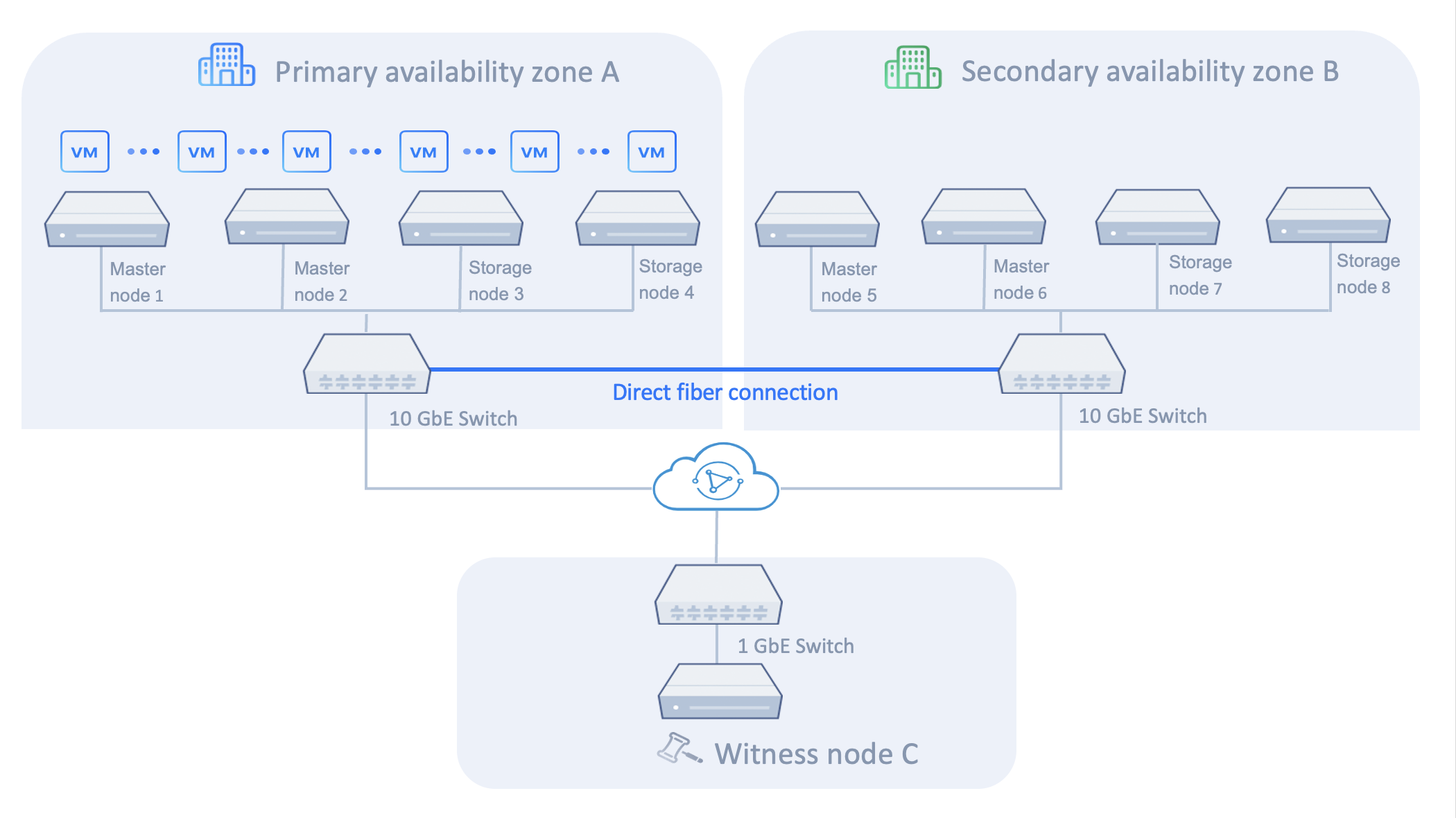
In an active-active cluster, both the cluster-level primary availability zone (IDC A) and the secondary availability zone (IDC B) can run workloads. Each virtual machine selects the availability zone in which it normally runs as its primary availability zone. The system behavior in response to node failures in either availability zone is generally the same. In this example, it is assumed that the virtual machines are expected to run stably in IDC A over the long term; therefore, IDC A is the primary availability zone for the virtual machines.
When HA is enabled in the cluster and placement group policies are configured:
Note:
Regardless of the type of failure, only up to 2 replications of data are preserved in a single availability zone, and it will not be restored to 3 replications.