Virtual machine high availability is an advanced virtual machine feature designed to ensure that virtual machines remain recoverable and available in extreme environments.
The diagram below illustrates the components and implementation principles of virtual machine high availability. The core logic relies on two components, Job Center and VM Monitor, to check iSCSI storage heartbeats and MongoDB heartbeats as the basis for high availability decisions.
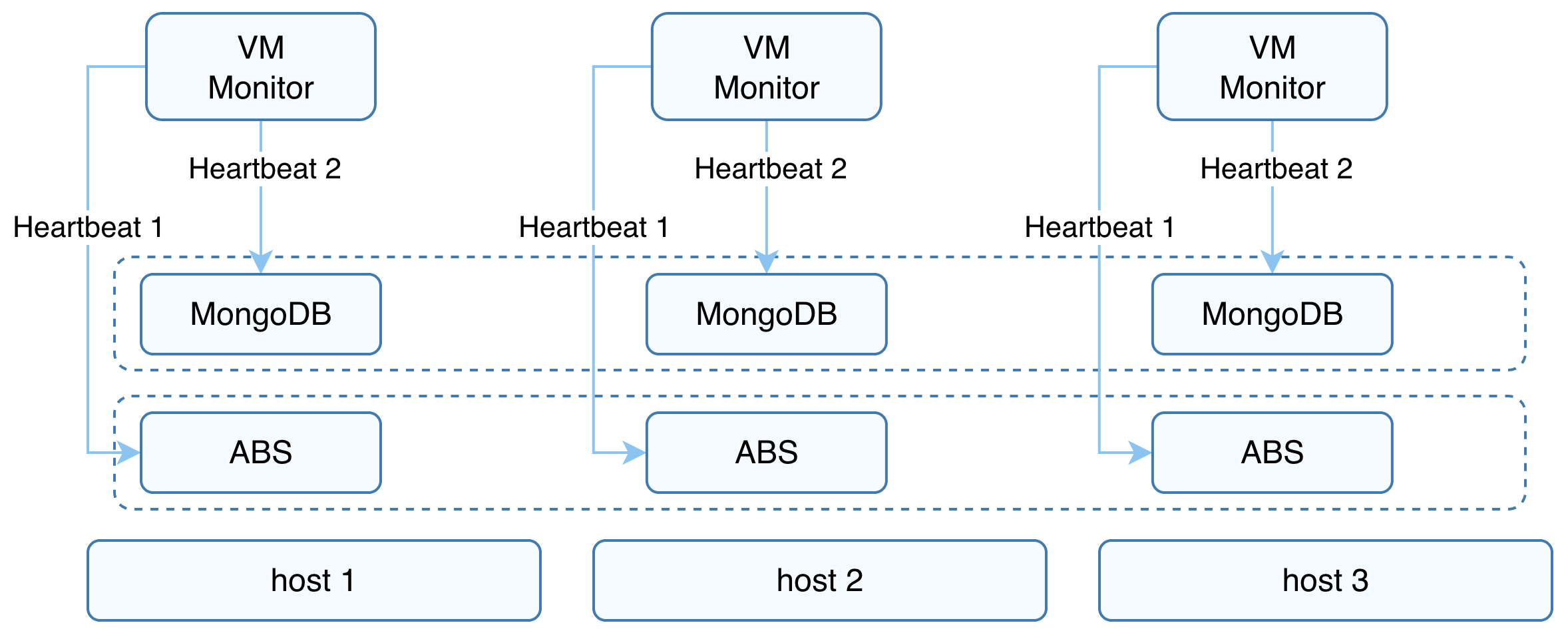
Guarantees
- Virtual machines with HA protection enabled will, under certain conditions, be rebuilt on healthy nodes in the cluster and restarted.
- A virtual machine that has triggered HA recovery must not, for any reason such as network jitter, result in two identical virtual machines running simultaneously on the same cluster, to prevent data corruption.
- The HA mechanism does not rely on the physical clock.
Trigger criteria
- When the cluster is healthy and one host experiences a power failure, storage network cable disconnection, storage network ifdown, filesystem entering read-only state, or shutdown, HA is triggered.
- Disconnecting a non-storage network cable (such as the management network cable) does not trigger HA.
- When the running state of a virtual machine with HA protection enabled is inconsistent with the state recorded in the database, HA is triggered to restore the virtual machine to the state recorded in the database (for example, if the QEMU process is killed). A voluntary shutdown initiated from within the guest OS does not trigger HA.
- If Boost mode is enabled on the cluster, a storage service failure triggers HA.
- If the cluster's HA failure scenarios are configured to trigger HA on VM network failure, HA is triggered when a VM network failure occurs.
- If the cluster's HA failure scenarios are configured to trigger HA on VM OS failure, HA is triggered when the virtual machine OS experiences a blue screen, kernel crash, or OS startup failure after HA is triggered.
Behavior
- Virtual machines with HA protection enabled will be rebuilt and started on healthy nodes in the cluster.
- If a node is isolated due to a network failure or special circumstances, all virtual machines on that node will first be suspended; if suspension fails, the virtual machines will be forcibly shut down.
- If a node is isolated due to a storage network failure, all virtual machines on the node will first be suspended, and HA will be triggered to schedule them to start on other nodes. Some virtual machines may fail to be scheduled to other nodes due to insufficient remaining cluster resources and will remain in a Suspended state. After the storage network recovers, virtual machines with HA enabled on that node (in the Suspended state) will automatically be restored to the state they were in before HA was triggered, rather than being restarted.
- If the entire cluster's storage network becomes unavailable due to a storage switch failure or other reasons, causing all nodes to be triggered into isolation, all virtual machines on the nodes will be suspended. Since there are no normally running nodes in the cluster, virtual machines will not be scheduled to other nodes. After the storage network recovers, virtual machines with HA enabled on each node (in the Suspended state) will automatically be restored to the state they were in before HA was triggered, rather than being restarted.
- If a node is isolated due to a storage network failure and all virtual machines on the node are suspended, and those virtual machines successfully recover to other nodes after HA is triggered, the cluster will automatically clean up the suspended virtual machines on the failed node once it recovers to a normal state.
- After 13 failed HA recovery attempts for a virtual machine with HA protection enabled, the virtual machine will be marked with its current actual state, and recovery operations will stop. The recovery interval is 10s for the first 5 attempts, 60s after the 5th attempt, and 100s after the 10th attempt. The maximum duration of the recovery state is 650s.
- For an AVE active-active cluster, if no VM placement group rules are specifically configured, HA scheduling follows the primary availability zone priority mode: when the resources on nodes within the primary availability zone are sufficient to meet the virtual machine's startup requirements, the virtual machine triggered for HA will always select a node within the primary availability zone as the HA destination.
- If a virtual machine triggered for HA due to a VM network failure has no schedulable hosts, the virtual machine will remain running on its current host, and the corresponding virtual NIC will display a network failure message.
- If the OS of a virtual machine fails to start after HA is triggered, the virtual machine will be restarted on its current host.
Performance
When a virtual machine with high availability enabled in the cluster fails, HA will be triggered within a certain time period, as shown in the table below.
| Failure scenario |
Failure detection sensitivity |
| Standard (default) |
Medium high |
High |
| Host failure |
Power failure, storage network anomaly |
130s |
100s |
60s |
| Filesystem read-only |
85s |
85s |
85s |
| VM status mismatch |
- |
- |
- |
| VM network failure |
65s |
45s |
35s |
| VM OS failure |
120s |
60s |
30s |
Note: When the system detects that the virtual machine state does not match the expected state, it immediately performs state recovery; therefore, HA trigger time is not applicable.